Keywords:要素,farポインタ,C,C++,アーキテクチャ
Cは「高級アセンブラ」とも言われるように,計算機の一般的な構成を知っていると学習に有利です.アセンブラ・プログラマから見た計算機の構成を「アーキテクチャ(architecture)」と呼びます. 計算機にはCPU(Central Processing Unit;中央処理装置)があって,メモリ(main storage)上の機械語プログラムを逐次読み込み,解釈し,実行します.パソコンなどのCPUには8本程度の16/32ビットの汎用レジスタ(general-purpose registers)があり,その内容は単なるビット・パターンとして使われることもあれば,add命令などでは2進(binary)の数値〔符号なし整数(integer)か,2の補数表現の符号付き整数〕として使われます.また,汎用レジスタはメモリ上のデータの位置を指すためにも使われます(インデックス・レジスタ;index register).メモリには8ビット(bit)〔1バイト(byte)〕ごとにアドレス(address)と呼ぶ一連番号が付いています. 浮動小数点(floating point;実数)の計算のために,32/64/80ビットの汎用レジスタとは別の浮動小数点レジスタが設けられることもあります.その内容は,国際的に標準化されています. C/C++言語はこれらハードウェアに密着した記述ができる高級言語です.つまりC言語の要素に直接対応しています.< copyright 1994 岡田好一 >トップに戻る
C/C++
CとC++は,従来BASICやFORTRANで書かれていた通常の応用プログラムをはじめ,機械に組み込まれたプログラムやオペレーティング・システムの中核部分,ワード・プロセッサなど応用プログラムの開発,他の高級言語のインタプリタ(interpreter)やコンパイラ(compiler)の開発などに応用され,多くのプログラマの絶大な支持を受けている,現在流行の計算機言語です. CとC++は大型機(mainframe)やワークステーション(workstation)を含む多くの機種で利用可能であり,パソコンでは複数のソフト・メーカが高品質なコンパイラを発売しています.経済的にも有利で,たとえば,パソコンで有名なBorland C++にはビジュアルな開発環境が付いているので,コンパイラのセットを買うだけで十分に応用プログラムの開発ができます. エディタ(editor)など多くのソフトには,C/C++での作業に便利な機能が付いています.システム側でもC/C++でのプログラミングを考慮するようになりました.たとえば,Windowsなど最先端の応用ソフトのインターフェースが真っ先にC/C++に対して用意されます. 言語だけみた場合の生産性は,たとえば,LISPなどと比べて高いとはいえません.しかし,市販の参考書が多い,回りに知っている人がいる,パソコン通信で質問しても答えてくれる人がいるなど,支援環境(?)まで考えた生産性は,計算機言語の中でもトップ・クラスでしょう. Cに不安があるとすれば,Cが現在の計算機アーキテクチャにあまりにも依存しているため,未来の電算機でも効率がよいのかどうか定かでない点です.そして,スーパコンピュータ,超並列(massively parallel)計算機,並列推論(concurrent logical)計算機など,未来指向の計算機の研究が進んでいます.トップに戻るOR計算機アーキテクチャとC/C++に戻るC言語の要素
Cの変数はデータの入る記憶装置上の「場所」です.データの大きさは,charは一般にバイトであり,これは主記憶装置のアクセスの単位です.整数intは使用する電算機のレジスタの幅に合わせて,16ビットか32ビットです(パソコンのOSは急速に32ビット化されつつあるので,近い将来,intといえばすべての計算機で32ビット・データとなるでしょう).浮動小数点doubleは64ビットで標準化されています.ポインタはメモリ上のデータを,それがどこにあっても指すことができます. とくに80x86系では64Kバイトを越えるところを指すためにfarポインタが用意されています.トップに戻るOR計算機アーキテクチャとC/C++に戻るfarポインタ
farポインタはパソコンで使われている,Intel社の80x86系のCPUに独特の概念です.80x86系CPUは16ビットのレジスタで64Kバイトを超えるメモリをインデックスするために,メモリをセグメントに分け,セグメント番号とセグメント内の相対位置(オフセット)の両方で一つのメモリをポイントします.通常のプログラミングでも,Windowsプログラミングでも,コンパイラのラージ・モデルおよびコンパクト・モデルを選ぶと,自動的にポインタがfarとなるので,注意点は64Kバイトの境界を意識するくらいで,普段はテクニックを必要としません.問題は,スモール・モデルとラージ・モデルが混在する場合に起こります. 先に述べたように,Intel社の386以上のCPUの汎用レジスタは32ビットとしても使えるので,プログラミングも32ビット・レジスタによるCOMモデル(フラット・モデル)に移行しつつあります.farとnearポインタで今ほど悩むことは,今後はなくなるでしょう.トップに戻るOR計算機アーキテクチャとC/C++に戻るKeywords:スコープ,リンケージ,記憶クラス,データ空間,型,const
C/C++言語のデータの有効範囲は,スコープ(scope;通用範囲),リンケージ(linkage),記憶クラス(storage class)で考えます.つまり,プログラムの全体で使われるデータや,関数の中だけで使われた後,破棄される局所データなどを十分に把握して使わなければなりません. 実際のデータ空間はメモリ上のスタックやヒープ領域が使われます. またデータには必ず型があり,ANSI Cでは従来にくらべて細かく定められています.変数を一度初期化したら変更したくないときにはconst修飾子を使って定数化することができます.< copyright 1994 岡田好一 >トップに戻る
スコープ
スコープは,C/C++言語のテキストで変数や関数の名前が通用する範囲で,つまり,ソース・プログラム上の空間的広がりを指します.1ファイルに収められたC/C++言語のソース・プログラムを翻訳単位(translation unit)と呼びます. 関数や,関数のブロック中にない変数は,翻訳単位全体〔#defineや #includeがプリプロセッサ(preprocessor)で処理されてしまってからのプログラムが,コンパイラには見えることに注意〕から参照可能なので,大域的(global/file scope)と呼ばれ,関数の中のブロック({ }で囲まれた部分)中で宣言された変数は,ブロックの残りの部分でしか参照できないので,局所的(local)と呼ばれます. C/C++言語に,局所関数はありません.C++言語には,クラス(class)の中だけで通用する,第三のスコープがあります.C/C++のgoto文のラベルは関数スコープ(function scope)をもちます.トップに戻るOR変数や関数名の有効範囲に戻るリンケージ
C/C++言語には,ほかの翻訳単位で同じ名前の変数や関数を使えるようにするリンケージという規則があり,static/externで指示します.外部リンケージ,つまり,ほかの翻訳単位で同じ名前を使う場合,コンパイラが最終的な機械語を決められないので,その解決はリンカ(linker)にまかされます.トップに戻るOR変数や関数名の有効範囲に戻る記憶クラス
記憶クラスには,自動的(automatic/auto)と静的(static)の二つがあり,変数の寿命,つまり,実行時の時間的広がりを指定します.自動変数はブロックの実行が終わると,消滅してしまいます.静的変数は,プログラムが続く限り内容が保持されます.リンケージと記憶クラスは別の概念ですが,キーワードはstaticを使います. 一般に,変数などの記憶場所の時間的広がりを,エクステント(extent)と呼びます.C/C++には,静的,自動的以外に,プログラマが寿命を決めるヒープ領域(free storage)のデータがあります.Cではmalloc/free,C++ではnew/deleteの実行で,確保/開放されます.ヒープ領域のデータの入る場所には,名前がありません.必ず,ポインタで指しておく必要があります.トップに戻るOR変数や関数名の有効範囲に戻る型
型(type)は,データのビット・パターンをどう解釈するかの指定です.たとえば,long intは32ビットの2の補数表現の2進整数であるのが普通で,floatは32ビットの浮動小数点ですが,ビット・パターンをいくらながめても,それが整数か実数かはわかりません. Cでは,型情報はコンパイラが知っていて,long intの変数の処理では整数に関する命令が採用される,などとなります.だから,型情報は,機械語(machine language)の中に埋め込まれています.C++ではリンカ(linker)が型を知ることがあり(型保証リンケージ,type-safe linkage),複雑なクラスのオブジェクトでは実行時にも,ある種の型情報が保持されます. Cには多くの型がありますが,charとintとdoubleとポインタの違いがわかれば,あとはもっぱら構造体の定義で使われると考えればよいでしょう.トップに戻るOR変数や関数名の有効範囲に戻るconst/volatile
const修飾子は,大域変数,局所変数,関数の仮引数に指定し,初期化できるが代入できないオブジェクトを指定します.C++では,constオブジェクトに使用する可能性のあるメンバ関数,つまり,データ・メンバを変更しない,印字や内容報告のメンバ関数にはconstを指定します. constのない参照は,実引数(actual argument)で指定されたデータの場所,すなわち左辺値(lvalue)の内容を変えるかもしれません.左辺値でない実引数(一般の式や定数)が予想される場合,つまり,入力として参照を使う場合は,仮引数にconstを指定します. volatile修飾子はオペレーティング・システムやハードウェアが内容を不定期に書き替えてしまう可能性のあるデータの指定です.つまり,コンパイラが一定期間の内容の不変を前提としないなど,最適化を抑える働きがあります.トップに戻るOR変数や関数名の有効範囲に戻るKeywords:構造体,配列,ポインタ,文字列,共用体,列挙型
C/C++のcharやintなどの整数と,floatやdoubleなどの浮動小数点数,およびvoidを基本型といいます.基本型は,計算機アーキテクチャと密接な関係があります. それに対し,配列(array),関数(function),ポインタ(pointer),リファレンス(参照reference),定数(constant),クラス(class),構造体(structure),共用体(union),列挙型(enumeration),クラス・メンバへのポインタ(pointer to class member)を,単独で,あるいは組み合わせたものを派生型といいます.< copyright 1994 岡田好一 >トップに戻る
配列,ポインタ
配列は,基本型や構造体などを連続して記憶装置上に並べたものです.列挙型
文字列
C/C++の文字列は,charの配列でデータの最後に\0の要素を加えたものです.ですから,\0を文字列に含ませることはできませんし,配列は最大の文字列長+1を確保しておく必要があります.string.hで定義されている文字列操作の関数は高速で,最適化されることもあります.したがって,BASICと違うなどと好き嫌いを言わず,積極的に利用したほうがよいでしょう.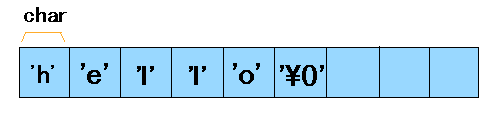
共用体
共用体は,違う型のデータが同じ領域を使うように指示するもので,その大きさは,最大の型の大きさが入る大きさとなります.実際にどの型のデータが入っているかは,実行時に別ルートで手に入れる必要があります.トップに戻るOR派生型に戻るKeywords:宣言,定義,デフォルト引数,参照,関数の多重定義
C/C++言語の「関数(function)」は,引数の値から結果の値に写像(mapping)する,まさに関数として使われることも少なくありませんが,入出力関数のように,途中の動作,つまり「関数の副作用(side effect)」を利用するサブルーチン(subroutine)的な使われ方のほうがむしろ多いでしょう.つまり,C/C++の関数は,計算処理を細かく分解していくときの単位です. C/C++では,関数や演算などの式(expression)にセミコロンを付けただけの「式の文」(expression statement)が多く,残りの文は,複文(compound statement)やif,forなどの実行の制御のための文です. C/C++では,プログラムの最初に呼ばれるmain関数からして関数です.関数を使用するには宣言が必要で,その中身は定義で記述します. 一つの関数の仕事は,一息で説明できる程度の小ささが望ましいでしょう.込み入ったwhileループなどを作ってしまうと,後で管理できなくなるからです.< copyright 1994 岡田好一 >トップに戻る
関数の定義
関数は,どこかで定義(definition)しないと,当然ながら,機械語は生成されません.
double func1(int n, double x, char *c) {
return double(n) + x + double(c[0]) ;
}
使わない仮引数の変数名は,書かないほうがよいでしょう.
double func2(int n, double x, char*) {
return double(n) + x ;
}
C++では引数の多くが決まった値が使われるときなどではデフォルト引数(default arguments)を使って読みやすくすることができます.さらに,C++では引数に参照を使いすっきりと表現することもできるようになっています.また,引数の型が違えば,C++では関数の多重定義もできます.関数の定義は宣言でもあります.トップに戻るOR関数の定義に戻るデフォルト引数
関数の多重定義
C++では,関数の多重定義(overload)も可能です.つまり,引数の型のみが異なった同じ名前の関数を宣言し,別々に定義することができます.リンカが混乱しないように,リンカに渡す関数の名前が引数の型によって拡張されます(型保証リンケージ).トップに戻るOR関数の定義に戻る関数の宣言
関数を使用する(ソース・ファイルの位置的な)前に,そのスコープ内で宣言(declaration)が必要です.参照
C++の仮引数には,参照(reference)を使うことができます.Keywords:型,フレンド関数,メンバ関数,コンストラクタ,デストラクタ,オブジェクト,オブジェクト指向,静的メンバ,コピー・コンストラクタ
C++のクラス(class)はCの構造体にアクセス制御(access control)を付加し,メンバに関数を書けるようにしたものです.つまり型の拡張といえます. アクセス制御は,メンバがグローバルに参照できるのか(公開部public),メンバ関数(member function)とフレンド関数(friend function)のみで参照できるのか(非公開部private)を決めます.< copyright 1994 岡田好一 >トップに戻る
フレンド関数
フレンド関数は,あるクラスからfriendと指定された関数で,そのクラスの非公開部にアクセスできる関数です.フレンド・クラスは,あるクラスからfriendと指定されたクラスで,そのクラスのメンバは,指定元のクラスの非公開部にアクセスできます. フレンド関数は,複数のクラスのフレンドになれます. フレンド関数の引数には,必要なら型変換(type conversion)が行われます.+や*など,交換法則が思い浮かぶ演算子の定義にフレンド関数を使うと,左右どちらにでもねらいのオブジェクトを配せるので便利です. この場合,intなどから,ねらいのオブジェクトに変換する変換コンストラクタ(引数がintなどのコンストラクタ)を,プログラマが用意しなければなりません.トップに戻るORクラスに戻るクラスと型
クラスは型の概念の自然な拡張になっています.どちらも,データの記録としての内部状態をもち,データの処理の目的のための関数や演算を備えています. ただし,C++では,言語で用意されているintやdoubleなどの型に,利用者が機能を追加すること(たとえば,派生クラスを派生させること)はできません.トップに戻るORクラスに戻るメンバ関数
オブジェクトの非公開部のデータ・メンバの操作は,メンバ関数で行います. メンバ関数の呼び出しは,静的メンバ
static指定のデータ・メンバ,すなわち静的データ・メンバはオブジェクトに付属するのではなく,大域変数と同じくプログラム全体で実体は一つしかありません. しかし,同じクラスのメンバ関数か,フレンド関数からしか見えない変数です.オブジェクトがいくつ作られたかなどの,クラスの管理情報に使うと便利です.トップに戻るORクラスに戻るオブジェクト指向,メッセージ,インスタンス
C++では,Cと同様のプログラミングも可能ですが,main( ) 以外の関数は,できるだけメンバ関数にするのがよいでしょう.なぜなら,構造体と同じく,クラスには使う目的があり,メンバ関数によるデータ・メンバの操作が,その目的の実現と考えられるからです.そして,データ・メンバを非公開部に入れるのは,目的以外の不適当な操作から守るためです. メンバ関数の呼び出しを,そのオブジェクトにメッセージ(message)を送ると表現します.メッセージを送られたオブジェクトは,内部状態(データ・メンバの値)を報告したり,変更したり,さらにほかのオブジェクトにメッセージを送ったりします.そのような見方をすると,オブジェクト(オブジェクト指向のデータ)は,メッセージに対する自分自身の振る舞い方を知っていると表現されるのが理解できます. オブジェクトの集合とメッセージのやり取り(メッセージ伝達;message sending)でプログラムするのが,オブジェクト指向(object oriented)プログラミングです. クラスから生成されたオブジェクトは,データとしてクラスを実体化したものと言えるので,特にインスタンス(instance)と呼ぶことがあります.C++では,オブジェクトはほぼインスタンスと同義ですが,クラスもnew演算子というメッセージを受け取ると考えられるので,オブジェクトということがあります.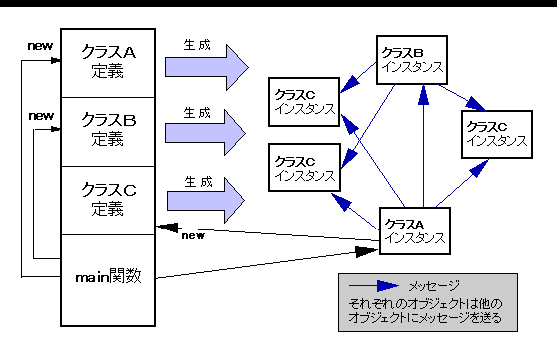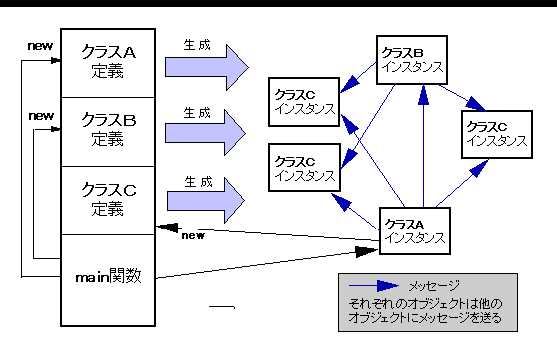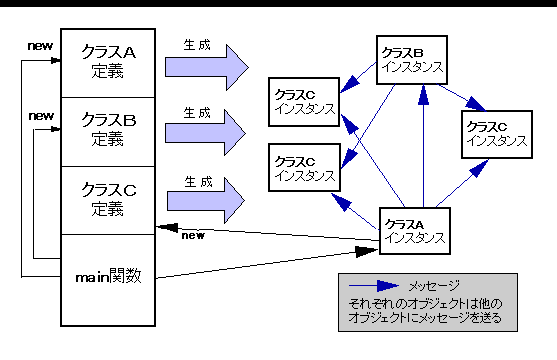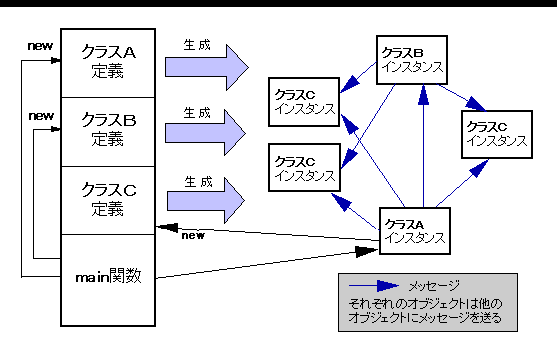
コンストラクタとデストラクタ
非公開部のデータ・メンバがあるような複雑なオブジェクトの生成時には,場所の確保以外の準備,つまり,初期設定が必要な場合があります.初期設定(initialization)は,コンストラクタ(constructor)と呼ばれる特別なメンバ関数が行います.C++の文法上の都合でコンストラクタが必要な場合は,自動的にコードが付加されます. コンストラクタは,複雑なオブジェクトの生成時には必ず呼ばれるので,初期化で行う作業が必要なときには,プログラマがコンストラクタを定義すると便利です.たとえば,クラスにはポインタだけがあり,実体はnewなどでそのつど付け加えないといけない場合などです. データ・メンバにポインタがあるときは,コピー・コンストラクタをプログラミングするかどうかを決める必要があります. コンストラクタに対応して,複雑なオブジェクトの消滅時には,デストラクタ(destructor)が自動的に必ず呼ばれます. オブジェクトの消滅時には,適切なデストラクタが起動しなければなりませんが,直接には型情報を手に入れにくいことが多いでしょう.基本クラスへのポインタが使われる場合は,デストラクタを仮想関数と定義すれば間違いがありません.トップに戻るORクラスに戻るオブジェクト
クラスは単なる定義であり,データとして使うには,クラスからオブジェクト(object)を生成する必要があります.C/C++では,(参照以外の)変数はデータの入る領域なので,変数はオブジェクトです.大域変数と静的局所変数は,プログラムの開始時に生成され,終了時に消滅します.自動変数と仮引数は宣言時に生成され,ブロックの終わりで消滅します.ヒープ領域のオブジェクトはnew演算子で生成され,delete演算子で消滅します.トップに戻るORクラスに戻るコピー・コンストラクタ,代入演算子
コピー・コンストラクタは,同じクラスのオブジェクトのデータに基づいてオブジェクトが初期化される場合,たとえば,関数の仮引数や値を返すときなどに起動します.コピー・コンストラクタを書かなければ,メンバごとのコピーが行われます.たいていはそれで十分ですが,たとえば,データ・メンバにポインタがある場合,ポインタの先のデータはコピーされないので,単純コピーなら同じ実体を指してしまいます.もし,ポインタの先のデータもコピーしたいのなら,コピー・コンストラクタと代入演算子の再定義を書きます.トップに戻るORクラスに戻る抽象化
「抽象化」は,中身を隠してインターフェースのみを公開する,C++のクラスのような問題の組み立て方を指します.しかし,その目的には二つの方向があるので注意が必要です. 一つは,C++を含むオブジェクト指向でよくいわれる,「クラスの共通性を抽出」する方向で,いわば,応用問題から,機械語のような単純な方向に向かって「抽象度」が増すものです. もう一つは,「抽象データ型(abstract data type)」で議論される,機械語こそが具体的なのであり,問題が高度化するにつれ,抽象的なデータ構造や操作,つまり高級言語を必要とするというとらえ方です. もちろん,だれが考えても,両者は「抽象化」の方向性がまったく逆であり,その違いを意識しなれば,大混乱に陥るでしょうし,実際に,業界には混乱が見られます.哲学の先生にこの問題を話したら,前者は「オブジェクト(対象)の抽象化」であり,後者は「形式の抽象化」であると,さっそく名前を付けてくれました.トップに戻るORクラスに戻るKeywords:仮想関数,抽象クラス,多相性
あるクラスに,データ・メンバやメンバ関数を付け加える操作が継承(inheritance)です.付け加えられるクラスを基本クラス(base class),付け加えた結果のクラスを派生クラス(derived class)といいます. 派生クラスのインスタンスには,派生クラスで付け加わったデータ・メンバのほかに,基本クラスで定義されているデータ・メンバの場所も確保されます.ただし,基本クラスのデータ・メンバへのアクセスは制限されることが多いでしょう.そのような場合は,基本クラスの公開されているメンバ関数を使って,自分のインスタンスの中にあるデータ・メンバにアクセスします. いずれにしろ,基本クラスのもつ性質(データ,関数)が派生クラスに受け継がれたので継承といいます.たとえば,ただのウィンドウ(基本クラス)にワープロとしての機能をもたせたワープロのウィンドウ(派生クラス)も,依然として画面上を移動でき,大きさを変えられ,アイコン化できます. 基本クラスの記述には手を付けず,派生クラスで基本クラスを指定します.基本クラスからは派生クラスの内容はわからないし,同じ基本クラスから派生した二つの派生クラス同士も,どのようなデータ・メンバやメンバ関数が,ほかの派生クラスで加わったかはわかりません.実行時も,派生クラスのないクラスのインスタンスと,派生クラスのある基本クラスのインスタンスとの違いはありません. また,基本クラスが二つ以上ある派生クラスを作ることができます.これを多重継承(multiple inheritance)といいます. 基本クラスの構成を変更することなく基本クラスの機能を利用するために仮想関数というしかけがあります.< copyright 1994 岡田好一 >トップに戻る
仮想関数
派生クラスのインスタンスは,キャストなしで基本クラスへのポインタで指すことができます.その結果,たとえば,基本クラスへのポインタの配列の個々の要素がその基本クラス,およびそれから継承された派生クラスのインスタンスを混在して指すことができます. ポインタの先にある異なるクラスのインスタンスは,その大きさが異なるかもしれませんが,ポインタの値の交換などによって配列の中の順番の変更などが可能となります.つまり,基本クラスが同じであれば,異なるクラス(型)のデータを一つの「容器」に自由自在に格納することができます.通常,容器のクラスはその中身である要素のクラスとは継承の関係がありません.これらをコンテナ・クラスと呼びます. 仮想関数(virtual function)は,基本クラスへのポインタに作用させたとき,正しい派生クラスのメンバ関数を実行するためのしかけです.通常,上記のような「クラスの混在可能な容器」のクラスの存在を前提とし,要素のクラスに仮想関数があります. 仮想関数により,switch/caseを使わなくてもデータに応じた処理が可能なだけでなく,新たに派生クラスを作っても,基本クラスの構成を変更することなく,基本クラスの機能を利用することができます.見方を変えれば,混在クラスの共通性をまとめたものが基本クラスであり,派生クラスのデータへの操作の,しかし,各クラスに共通する機能(たとえば,内容の印字など)を仮想関数にしておく,となります. 基本クラスで仮想関数の定義を使いたくない場合,純粋仮想関数(pure virtual function)という書き方をします.純粋仮想関数が一つでもあるクラスのインスタンスは生成できません.このようなクラスを抽象クラス(abstract class)といいます. クラスの混在を「多相性(多態,polymorphism)」と呼びますが,「データ自身が自分の処理方法を知っている」オブジェクト指向では特別ではありません.むしろ,仮想関数でない通常の関数がオブジェクト指向の基本を破っています.しかし,C++では,通常の関数に比べて仮想関数は効率が悪いので,必要な場合以外は使わないほうがよいでしょう. 効率を重視するときにテンプレートを使うことがあります. 仮想関数の実現のために,内部的には,関数へのポインタの配列(関数テーブル)が使われます.
Keywords:入出力ストリーム,コンテナ・クラス・ライブラリ,ウィンドウ
C++のクラスは,型に相当します.したがって,クラスを定義することは,C++言語を拡張することだといえます.クラス・ライブラリ(class library)を用意することは,いわば,新たな計算機言語を設計することに匹敵します.これは簡単な作業ではありません. しかし,クラス・ライブラリの充実はC++の使いやすさの鍵を握っており,C++の普及の状況から考えて,できるだけ早期の標準化が求められているといってよいでしょう.幸い,役に立つクラスのパターンは,入出力ストリーム,コンテナ・クラスやウィンドウのようにそう多くはないと思います.< copyright 1994 岡田好一 >トップに戻る
ウィンドウ
ウィンドウ(window)・システムは,クラス・ライブラリ化が可能です.ウィンドウ・システムは,本来オブジェクト指向的な性格があるので,クラス・ライブラリによく似合います. つまり,ウィンドウ・システムで表示されるウィンドウやアイコン,ボタンなどは,どれもウィンドウとしてのデータ(位置や大きさ)を保持しなければなりませんし,最低限のウィンドウの動作(移動,削除)は必要であり,それに,固有の動作が加わっていきます.そして,どのウィンドウも,ウィンドウとしてお互いの位置関係やマウスやキーボードの入力対象などが一元的に管理されるでしょう. この関係は,基本クラスと派生クラスの関係にそっくりであり,実際,そのようにウィンドウ・クラスは設計されます.トップに戻るORライブラリに戻るテンプレート
コンテナ・クラスにおける「クラス混在の可能な」はオプションであって,実際には,同じクラスしか扱えない待ち行列やリストでも十分に役立ちます.クラスが混在しない場合は,仮想関数は冗長であり,マクロ(macro)で記述が可能です.型を引数とし,クラスを作るマクロを生成的クラス(generic class)といいます. C++では,マクロを使わなくても,「テンプレート(template)」を用いると,型やクラスがパラメータとして使えるので便利です.テンプレートはコンパイラの機能ですから,型チェックの結果が報告され,マクロの副作用〔マクロは字面だけを見て展開(expand)するので,書いたつもりでない展開の起こる確率が言語で定義された機能を使うよりも多くなる〕もなく,デバッグの効率も上がるでしょう.トップに戻るORライブラリに戻るコンテナ・クラス
上述の「容器」のクラスは,具体的には,配列,待ち行列,リストや木構造で,一般にコンテナ・クラスと呼ばれます.コンテナ・クラスの処理をする場合,個々の要素に次々にアクセスするために,ポインタ的なオブジェクトを設けることが多いでしょう.そのオブジェクトを反復子(iterator)と呼びます.通常,容器と反復子には,継承の関係はありません.トップに戻るORライブラリに戻るコンテナ・クラス・ライブラリ
コンテナ・クラス(container class)は,それぞれのC++処理系で独自にライブラリ化されています.現在のところ,ANSI以前のC言語のライブラリのように,互換性はないようですが,ハッシュ(hash)表やBtreeなど,生産性を向上させる機能が使えるようになるので,使えれば使うにこしたことはありません. LISPでは,Common LISPなどで導入されたハッシュ表型が革命を起こし,従来のプログラミング・スタイルを変えてしまいました. たとえば,ファイル上の柔軟なBtree型がC++であたりまえに利用できるようになったら,COBOLなどは完全に過去の言語になってしまい,多くの第四世代言語は,その存在意義が消滅するのではないでしょうか.コンテナ・クラスは,そのような強力なパワーを秘めたクラスです.トップに戻るORライブラリに戻る入出力ストリーム
「入出力ストリーム」は,iostream.hをはじめとする,いくつかのヘッダ・ファイルで定義されている,C++で広く利用可能な,入出力操作のクラス・ライブラリです.Cのstdio.hに相当します. なお,ストリームとは,一般には,単に「データの流れ」を指しますが,C/C++ではファイル操作や入出力を指します. 入力には>>,出力には<<を用います.>>と<<の定義は,オペランド(演算対象)のクラスごとに再定義するので,利用者は型を意識せずにオブジェクトを並べるだけで入出力できます.C++には参照があるので,入力にアドレス演算子&を使わなくてもよくなります. 改行やフィールド幅の指定には,「ストリーム処理子」を使います.たとえば, cout << setw(6) << i << j << endl; は,整数iとjを幅6のフィールドに表示し,改行を付け加えます(この行の実行には,iostream.hとiomanip.hのインクルードを必要とする). プログラマは,ストリーム処理子を自由に追加することができます.トップに戻るORライブラリに戻る