文字集合
● ASCII/● ISO646
繰り返しになるが,文字集合(Character Set)は,その名のとおり世界中に存在するさまざまな文字の中から,利用する文字を集めた「使う文字の一覧表」である.
文字集合は,「面」という考え方を利用して,利用する文字を定義する.面とは,図1のように,縦横に格子状に連なったマス目になっており,この中に,文字を埋めていくわけである.面の縦横サイズは,文字集合によって異なる.また,一つの文字集合は複数の面をもつことができ,それは「第0面〜第N 面」のように数字で表現される.
| 〔図1〕面と文字集合 |
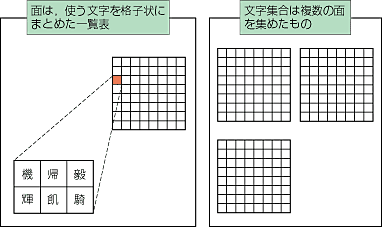 |
面の中のマス目には,それぞれ数値(コード)が割り振られている.面の中に存在する漢字は,そのコードを使って表現されるのが普通である.
一つしか面をもたない文字集合は,その面のコードをそのままでコンピュータで扱うこともできる.この場合は,文字集合がそのまま符号化方式となる.たとえば,ASCIIは8×16の128個のマス目の面一つをもつ文字集合だが,そのままASCIIという符号化方式としても利用される.
● ASCII
ASCIIは,1963年に米国規格協会〔ANSI(American National Standards Institute),当時の名称はASA(American Standards Association)〕によって定められた,文字集合/符号化方式である.ASCIIはAmerican Standard Code for Information Interchange(情報交換のためのアメリカ標準コード)の略で,8×16の面一つをもち,この中では7ビットで表現できる128個(0〜127)の文字/制御コードが定義されている.
ASCIIができる前,コンピュータには統一された文字コードは存在せず,それぞれのコンピュータで独自のコードが利用されていた.しかし,それではデータの交換ができないため,共通のコード体系が必要となり,ASCIIコードが作られたのである.
ASCIIコードは,図2のように34個の制御コードと94個の文字で構成されている.ASCIIでは文字の位置を表現するには,「05/12」のように縦横の位置で表現する.制御コードは00/00(NUL:ヌル文字)から02/00(SP:空白)と,07/15(削除)に配置されている.
| 〔図2〕ASCII文字集合 |
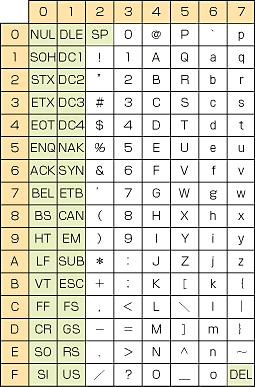 |
ASCIIコードは,現在の主要な多くの文字集合/文字コードの基本として利用されており,アメリカだけでなく世界の標準となっている.利用されている文字コードに関係なく,文字をコードで表すことをアスキーコード,と呼んでしまう場合もある.アスキーコードというのは,実際には特定の文字集合/符号化方式を表す言葉だから,こういった使い方は実際には誤用なわけだが,そのような誤用がされてしまうほど,標準的なコードとして普及しているということなのである.
● ISO646
ASCIIは,アメリカで作られた,アメリカで利用することを目的とした文字集合である.そのため,通貨単位を表す文字は$しかないし,アルファベットも,英語で利用するものしかなく,ドイツ語で使われている「![]() 」「
」「![]() 」や,スペイン語の「
」や,スペイン語の「![]() 」など,言語独特のアルファベット記号は表現できない.そこで,1967年に国際標準化機構により,ASCIIを元にしたISO646という規格が策定された.
」など,言語独特のアルファベット記号は表現できない.そこで,1967年に国際標準化機構により,ASCIIを元にしたISO646という規格が策定された.
ISO646は特定の文字集合を定義するものではなく,ASCIIを拡張し,独自の文字集合を定義するための決まりである.ASCIIだけでは自分たちが必要な文字に足りない,といった場合には,ISO646の決まりを元に,新しい文字を追加して,独自の文字集合を定義することができる.ISO646に基づいて策定された文字集合は,アルファベットや数字などの文字は,共通の位置におかれているため,最小限の互換性を維持できるわけである.
ISO646では,8×16の面を2枚もつことができる.第1面はASCIIとほぼ同じであるが,その中の12個の記号のコードに関しては,独自の文字に変更してもよいことになっている.変更してはいけない共通の文字をBCT(Basic Code Table)と呼ぶ.
そして第2面は,すべて自由に定義できる領域である.ただし,定義できるのは第1面で文字が定義されているのと同じ位置の94個だけである.第1面で制御コードとされている34個の位置には,第2面でも文字を定義することはできない.
| 〔図3〕ISO646で変更可能な文字 |
|
|
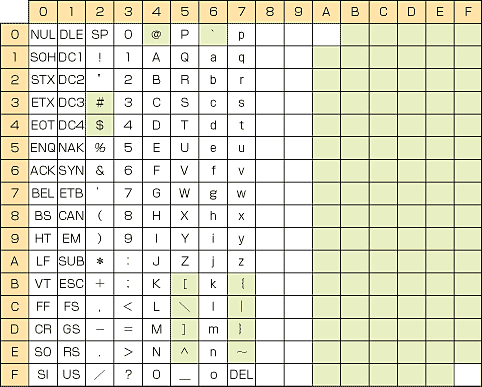
これらをまとめると,ISO646では図3のような位置に新しい文字を定義できることになる.この仕様を利用して,さまざまな文字集合が策定されている.たとえば,イギリスで利用されるBS 4730では「#」の代わりに「£」が含められている.ドイツで利用されるDIN 66 003では,ウムラウト付きのアルファベットなどを含む文字に置き換えられている(図4).日本でも「JIS X 0201」というISO646に準拠した文字集合が定められている.
| 〔図4〕ドイツ語の文字集合 DIN 66 003 |
|
|

ただし,コンピュータなどではこれら置き換え可能とされる記号が,特別な意味をもつ場合も多い.たとえば「@」などはメールアドレスでユーザー名とドメイン名を区切る記号になっている.そういった記号が置き換えられてしまうと,その文字集合を利用しているコンピュータでは,表示のされ方が変化してしまうため,あまり都合が良くない.そのため,ヨーロッパでは,ISO8859というASCIIとの互換性を重視した文字コード(コラム2参照)のほうが一般的になっている.
JIS X 0201においても,バックスラッシュ「\」を円マーク「¥」に置き換えているが,MS-DOSやWindowsではディレクトリの区切りをバックスラッシュで表現するため,日本語版のWindowsでは「C:¥WINNT¥java¥」のようにディレクトリの区切りがすべて「¥」になってしまう.
| コラム1 制御コード |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| コラム2 ISO8859 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|
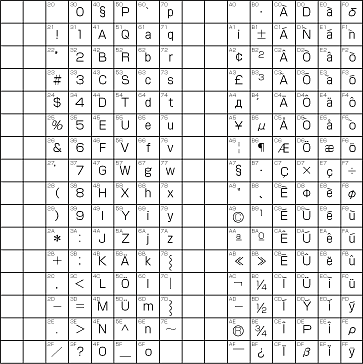
![]()
Copyright 2002 水野貴明